Last summer, I completed an internship for an experimental machine learning (ML) company. The main ML models they worked with are conditional random fields (CRFs), designed to take in a text document and label various parts of it according to the desired behavior.
In order to perform its labelling procedure, the model needs to be trained on a dataset. While the business had access to a large text-based dataset with which to train the model, the dataset still required significant preparation before it could be used. This dataset preparation involved:
Say you wanted a model to label parts of student transcripts. The original documents could come in a variety of formats, and would look something like this:
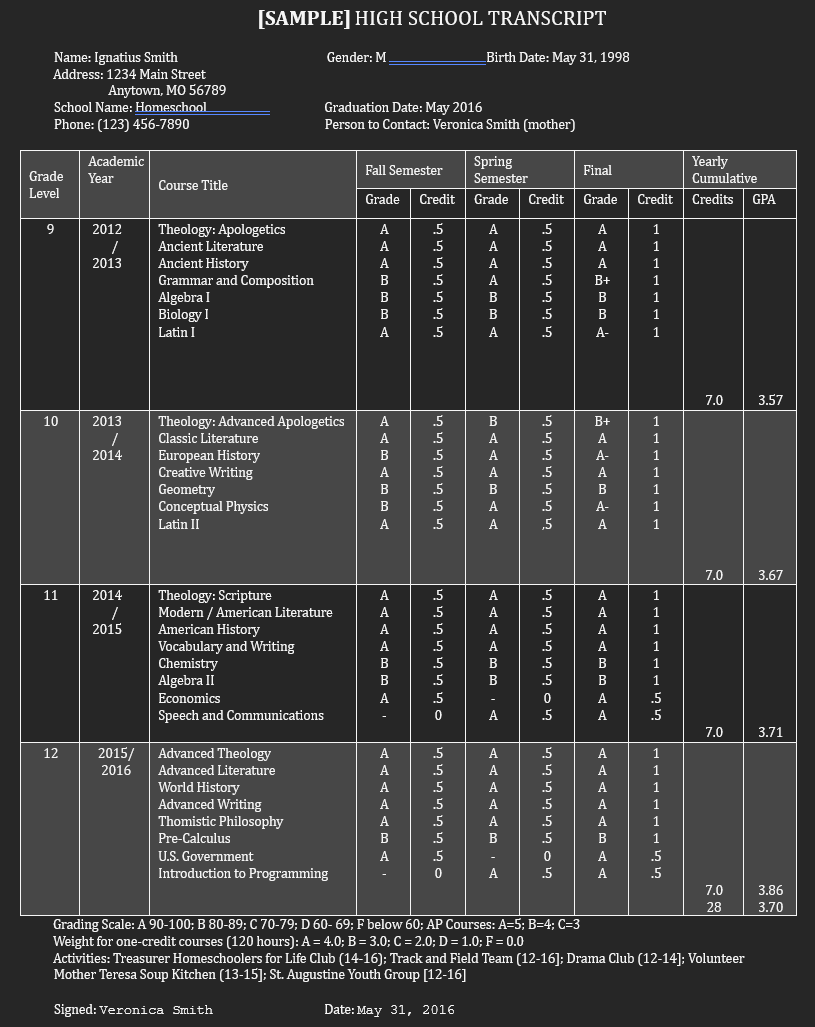
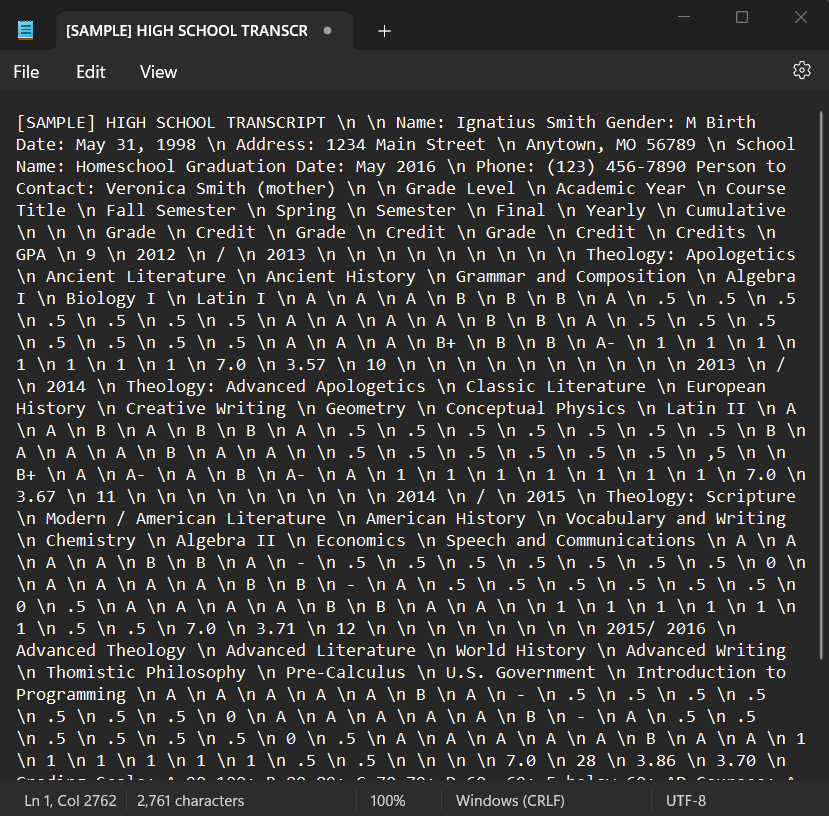
An annotator's job would be to first convert the document to a standardized text format. Line breaks and other white-space gets replaced by special characters, like "\n" (Note that all visual formatting is lost in the conversion, making the converted file difficult to navigate):
Then the desired segments would be copied into a format such as CSV (comma-separated values). If you wanted to label transcript information from each year including the year number, subjects taken, and GPA, an example set of annotations could look like this:

This process could be repeated tens of thousands of times depending on the application. As a result, there was an annotation pipeline. Text files were sent to designated "annotators", who would manually open each file, then copy and paste parts of the text into a special format to label it.
As an intern, I spent time as an annotator and became familiar with the process. It looked something like this:
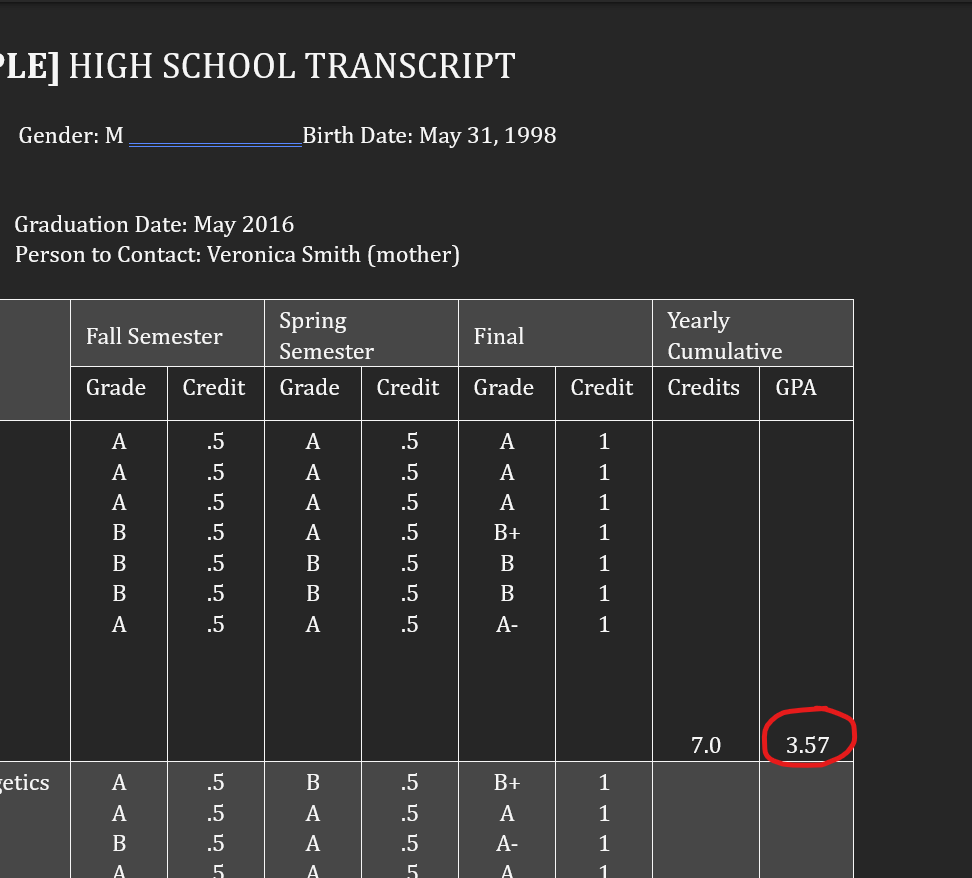
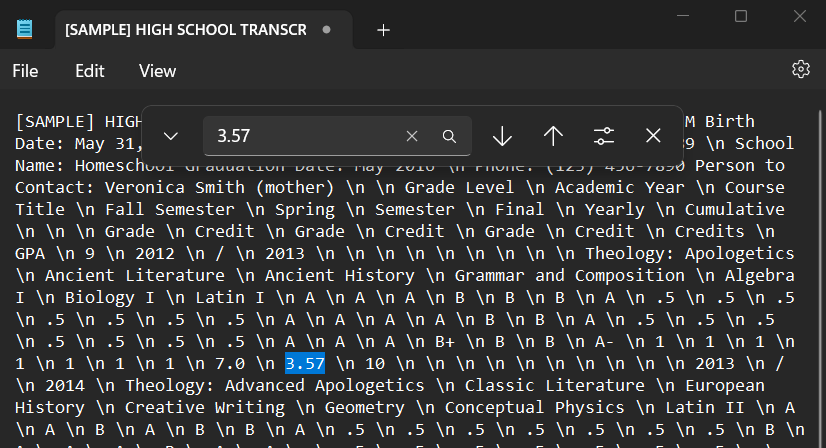

After several sessions annotating, I resolved to design a program to optimize the annotation process for myself and the other annotators working on the project. I defined this goal to fix these issues:
Goal: Make the annotation process as efficient as possible.
To make these features real, I had to make a standalone application. It is specifically intended for annotating various types of text files, where annotations consist of repeated associated data. Examples of this include data associated with each year of a student transcript (like GPA, courses taken, etc.), or information associated with cited sources in a bibliography (such as author, year published, etc.). Here is a tour of the program's primary features and a demonstration of the optimized annotation process on a folder of various file types.
Rather than opening files individually, the user selects a folder to annotate. As the user navigates the folder, files are automatically opened, converted, and presented to the user on the lefthand side of the screen:
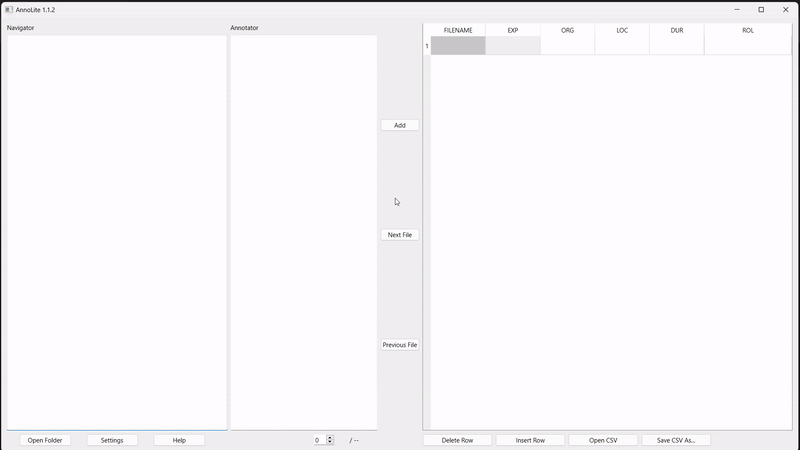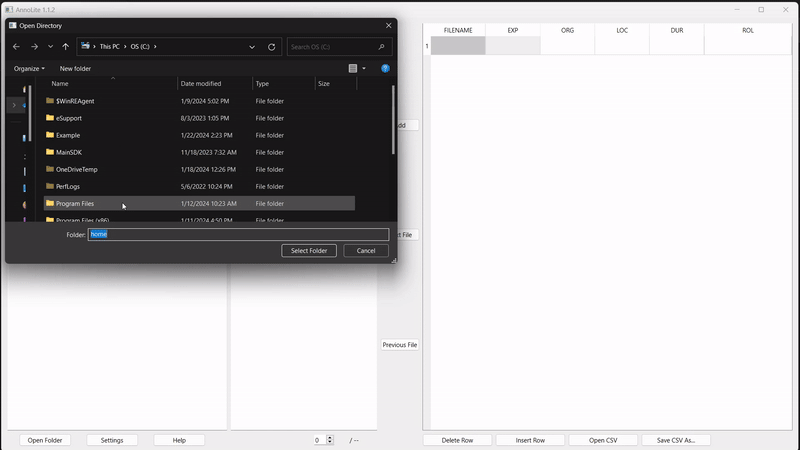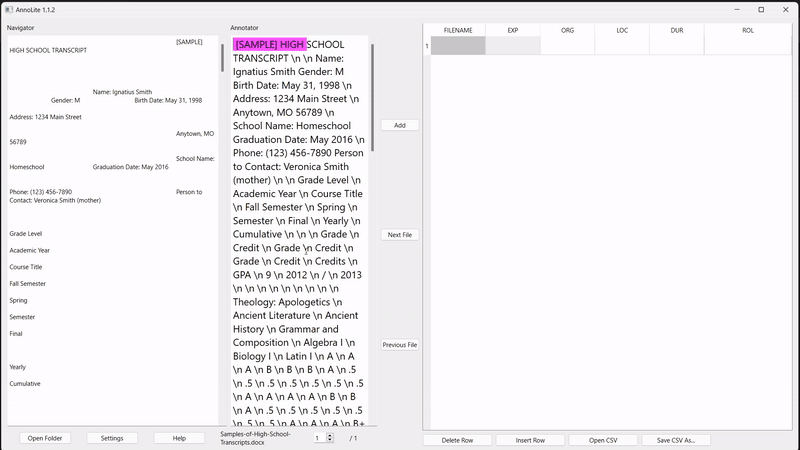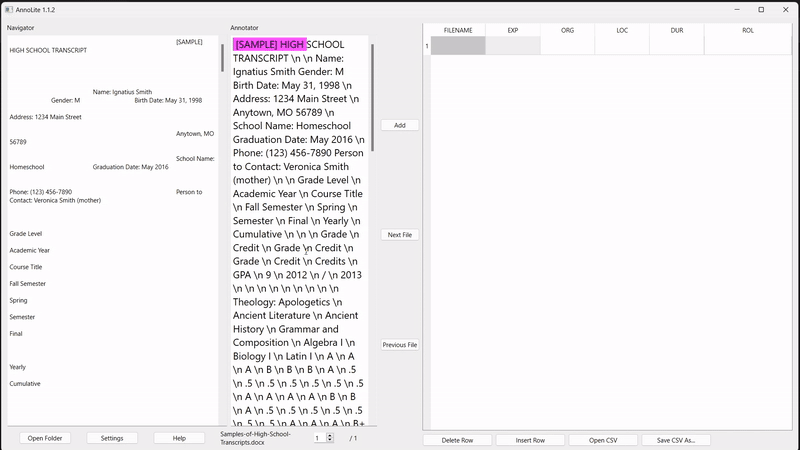
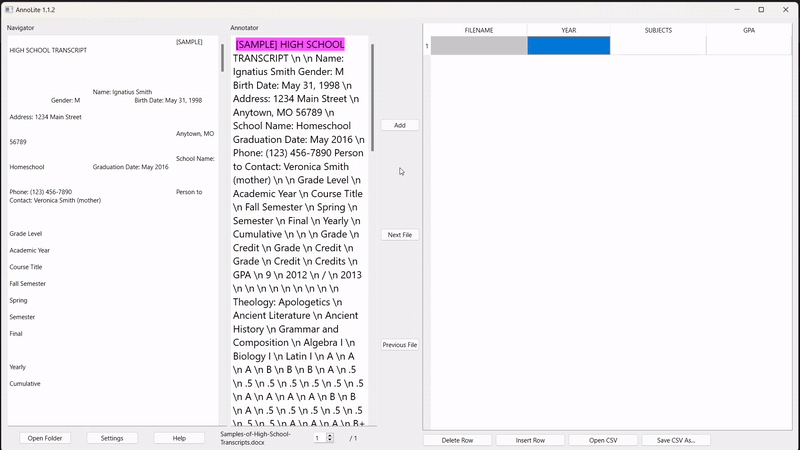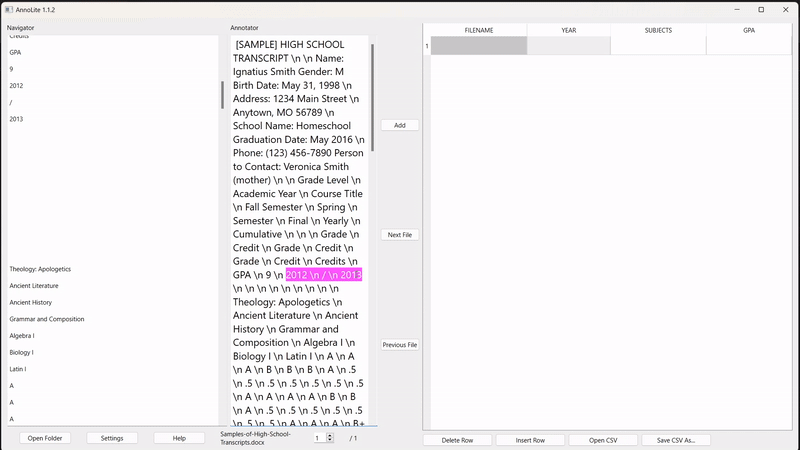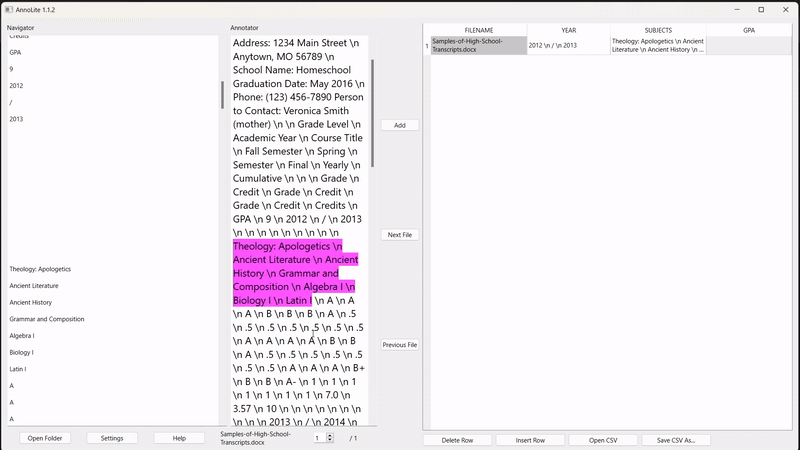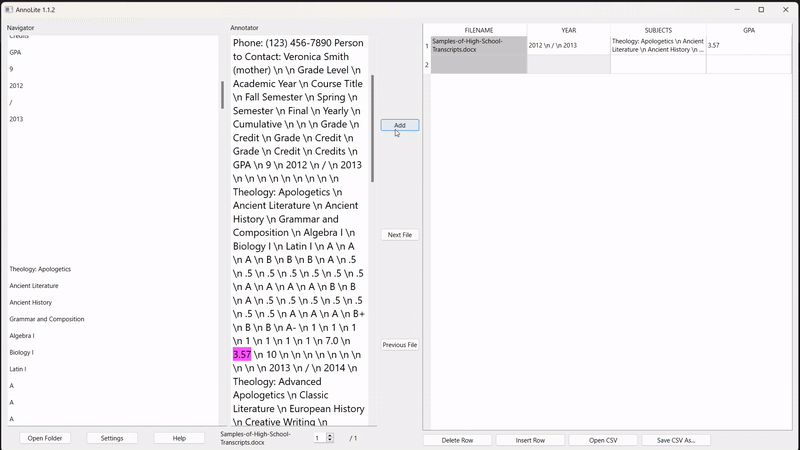
To eliminate the problem of having to find segments twice, the user can click anywhere within the formatted text on the left to automatically find the same segment within the converted text:
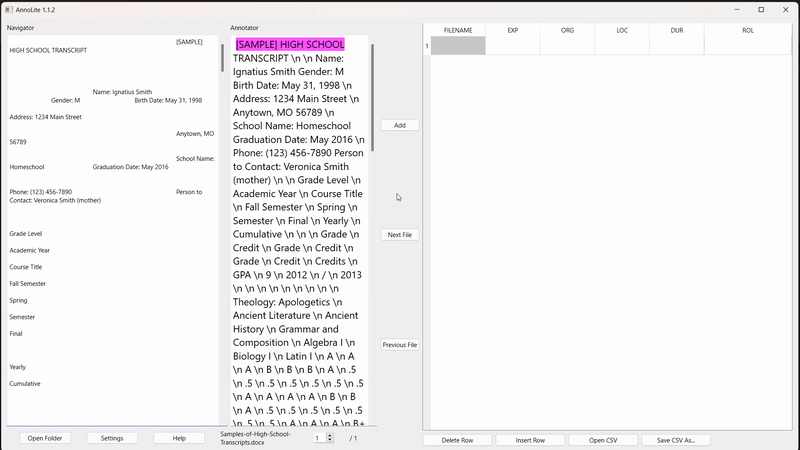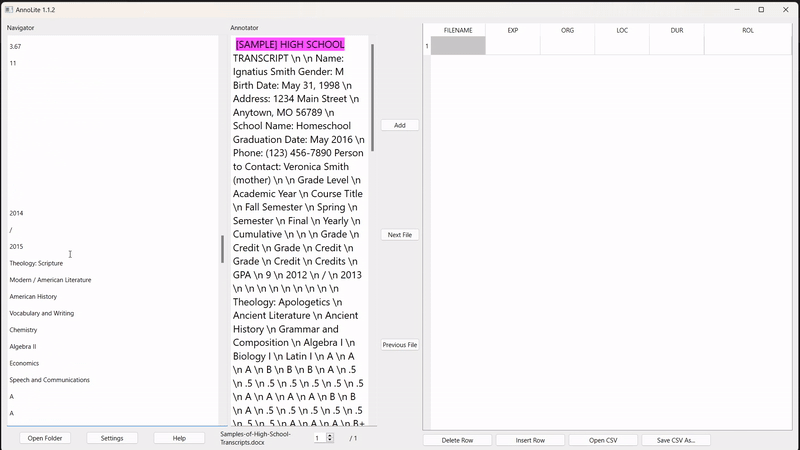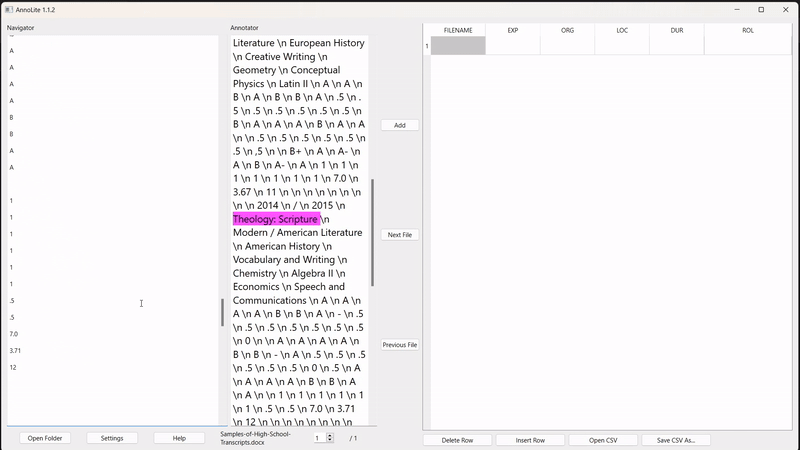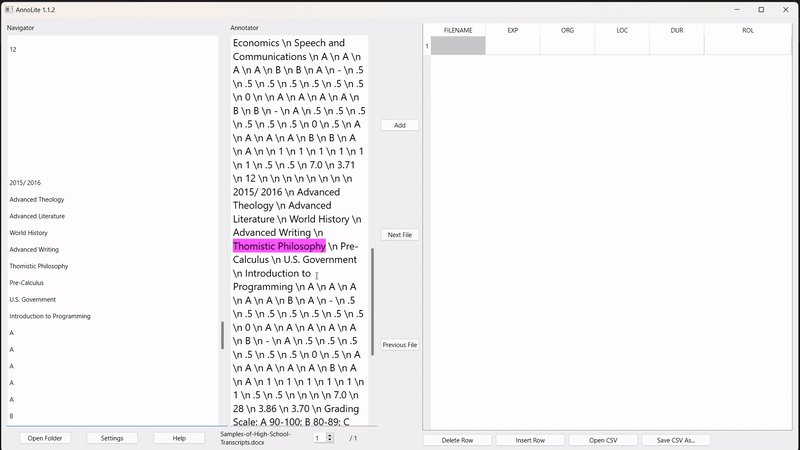
To annotate, the user highlights the desired segment in the converted text (in pink). Once highlighted, the "Add" button adds the annotation to the labelled grid on the right:
The output grid is exported directly to a .CSV file. There are also several quality-of-life features, such as being able to open and edit an existing CSV, insert and delete rows within a CSV, and autosave the CSV to prevent lost annotations.
Here is a video demonstrating the annotation of Word documents and PDFs with the final tool:
The saved CSV file looks like this.
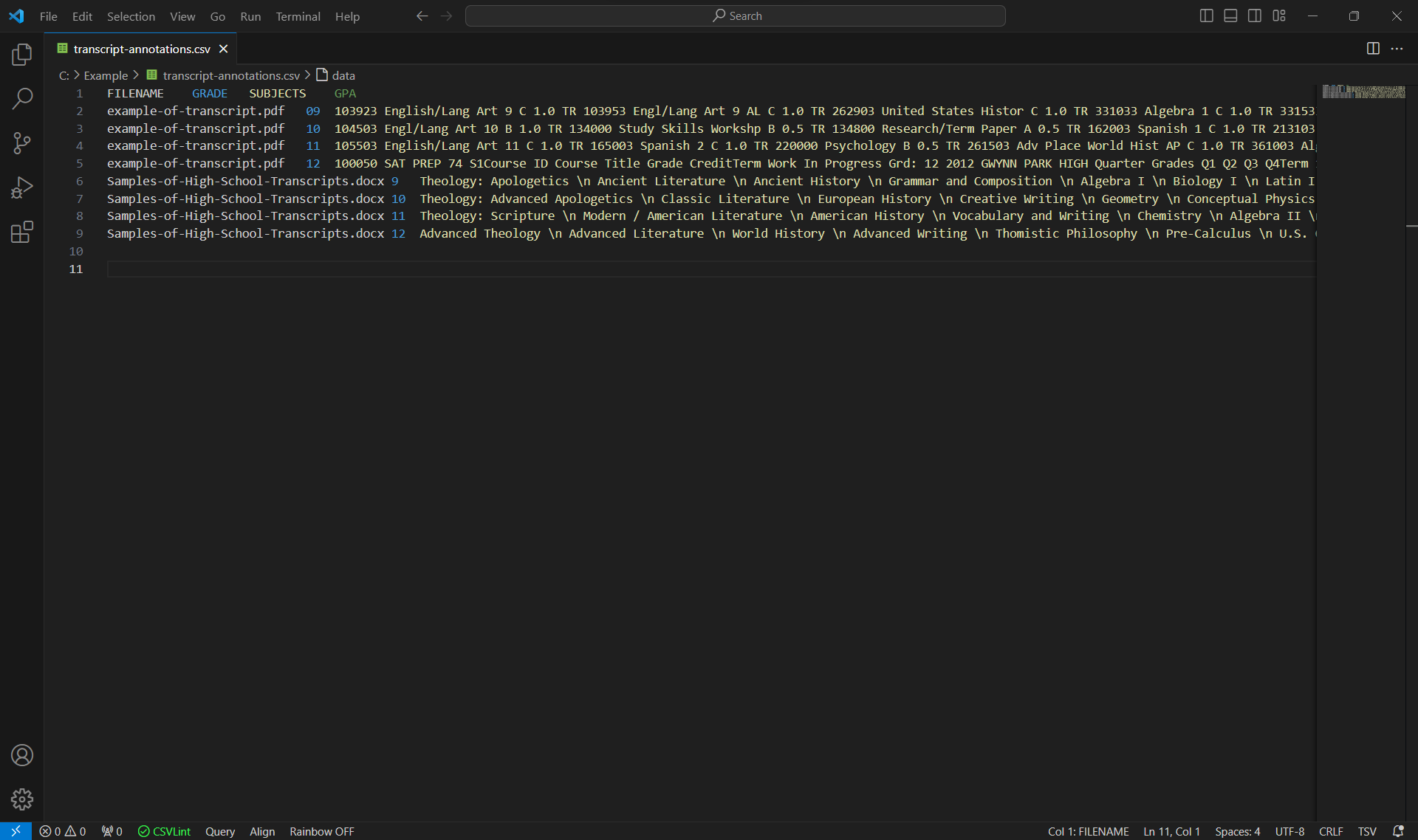
It can now be processed further, or be passed directly into a ML model for training.
After testing the tool myself, I presented it to my mentors. Towards the end of the internship, I got to train the annotation team, which then adopted its use. The development of this tool showed me that it can easily be worth investing time optimizing a process before beginning, as it can save significantly more resources in the long run.